WordTies
| Country: |
Denmark |
Presenter: |
Bolette Sandford Pedersen |
Presentation |
Website |
Link |
Description
WordTies is a web interface developed to visualize monolingual wordnets as well as their alignments with other wordnets. In this browser, the semantic relations are made available in a more intuitive and graphical fashion compared to what is found in most other wordnet browsers. It is often difficult to apply wordnets across languages because they expose very different structures. One question that one might want to ask is: What are the differences/similarities in the way wordnets are structured in the different European languages and are these differences rooted in actual cultural differences? Or can they rather be explained by the use of different compilation strategies: monolingually based, based on corpora, based on lexica/term lists, cross-lingually based (via translations) etc. A flexible and intuitive way of comparing such resources is to connect them through WordTies.
Other example questions that could be asked are: How are educational systems expressed in wordnets in the different European languages? Are the divergences rooted in actual differences in the educational systems across countries? How are food taxonomies expressed in terminologies/wordnets in the different European languages? For example, are cheeses structured differently from a taxonomical viewpoint depending on whether we in each particular country typically eat them as a starter, as a dessert or in a sandwich? Do we have comparable taxonomies for bread? Are these taxonomies changing over time due to more globalised eating habits?
WordTies was developed as a prototype in the METANORD project with the Nordic and Baltic countries. The impact of the browser will be increased by including more CLARIN partners and if more alignments are provided. We would be happy to be contacted by interested partners.
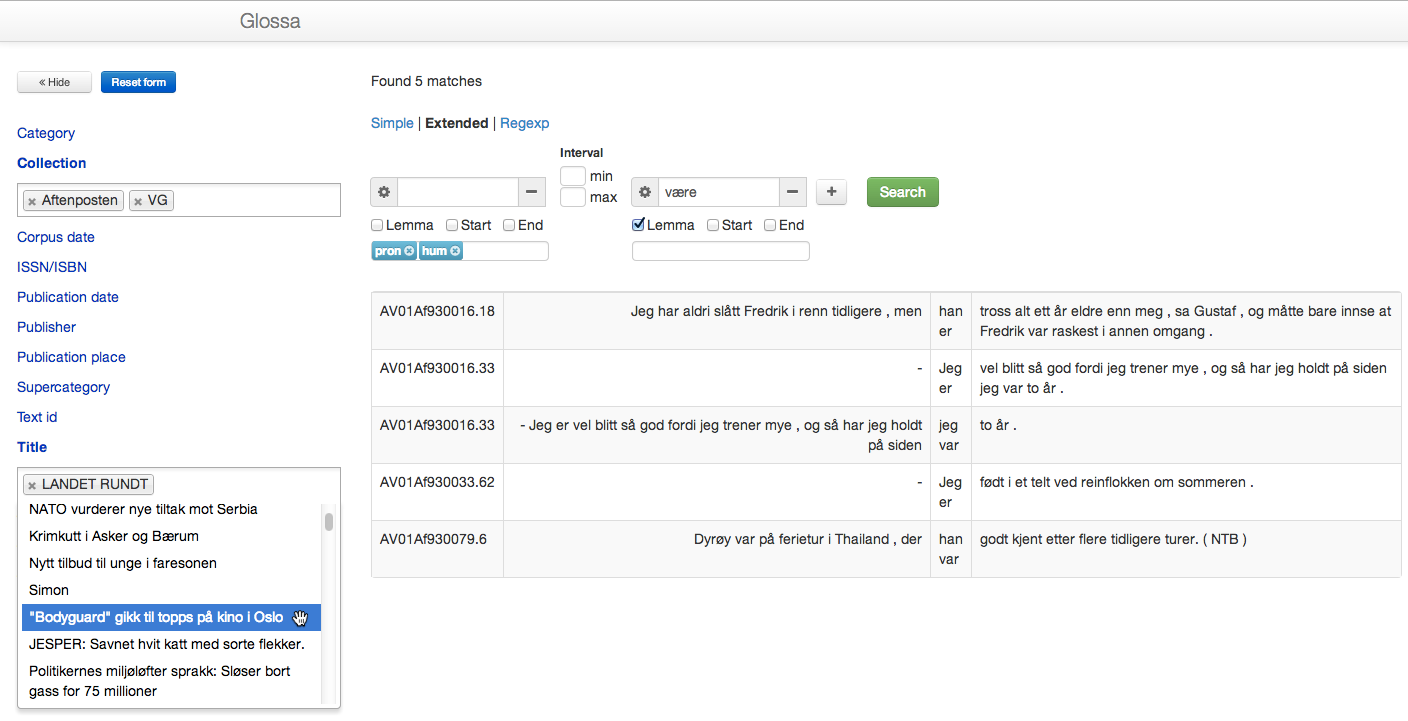
The Glossa corpus search system
Description
At the Text Laboratory, University of Oslo, we are currently developing a new version of our corpus search and post-processing tool Glossa. While the old version was tightly coupled to the IMS Corpus Workbench (CWB) and could only search in CWB-encoded corpora, the new version is flexible with respect to search engines and can even search in corpora located on other servers using the CLARIN federated content search. Incoming searches from other search agents in the CLARIN network are also supported (although support is not yet implemented).
The new version is much easier to install than the old version. This is particularly important with the possibility of federated content search since it means that even institutions that do not have any corpora of their own can install Glossa on their servers and use it to search the available corpora in the CLARIN network. Researchers will even be able to install Glossa on their laptops and use it to search CLARIN corpora or their own private corpora (creating a corpus building pipeline for Glossa is also part of the ongoing Norwegian CLARIN work).
The new Glossa version is undergoing heavy development, and significant parts of the functionality of the old version are still missing from the new one. However, federated content search with /CQL is already working, and searches in local CWB corpora support grammatical queries and metadata restrictions using three different search interfaces: a simple ("Google-like") search box, an extended view with menus and check boxes for specifying grammatical searches, and a regular expression view (the three views are kept in sync so as to enable switching between them while specifying the query).
Searching complex treebanks: the PML-TQ search engine and interface
Description
The PML-TQ search engine and interface (e.g. at
https://lindat.cz/services/pmltq/, described at
http://ufal.mff.cuni.cz/pmltq) allows for searching and displaying complex treebanks in many formats, including parallel ones. The interface allows text- or example-based query entry, tree display (SVG), and powerful postprocessing of results - from simple counting and aggregation of results (statistics) to extraction of
words, phrases, labels, or whole trees for further processing. Currently, 25+ treebanks (including the well-known ones such as the Penn Treebank, TIGER, PDT, etc.) have been converted to be indexed by the underlying search engine (database), and several of them are freely available for the public while others are being negotiated.
The engine and interface itself is freely available for anyone who might want to install it at their site; however, a web-service is being prepared to allow for remote access from complex web applications. The showcase will demonstrate the power of the engine and the search interface on several examples from different treebanks.
Searching multiple dictionaries and corpora: Keeleveeb query
Description
Keeleveeb is a portal, where one can run queries on several dictionaries and corpora. There are 12 Estonian monolingual dictionaries, 12 bilingual dictionaries (one of them Estonian), 19 Specialty dictionaries, 15 Learner dictionaries (bilingual, Estonian-Russian-Estonian), 23 corpora, and 3 tools integrated into the queries.
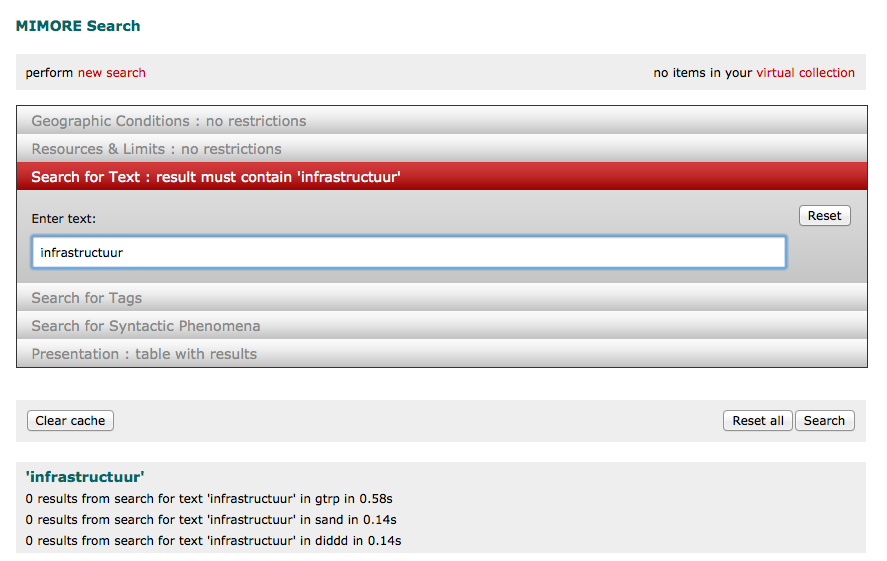
MIMORE
Description
The demonstrator tool MIMORE is a web application that enables simultaneous search in three micro-comparative databases on Dutch
dialects via a common interface. This makes it possible to investigate potential correlations between variables at the three different linguistic levels. Cartographic functionality enables the user to visualize these correlations and set theoretic functionality to analyze them.
WebMAUS
Description
The web application WebMAUS allows the user to automatically align speech recordings to their corresponding text form. Two input files need to be uploaded by the user: a media file containing a recorded speech signal and a file containing some textual encoding of the words spoken in the recording. In case the latter is a simple text, the contents are text-normalized and tokenized into a chain of words. The application then produces a phonological pronunciation encoding of the content in SAM-PA, that basically reflects the standard citation pronunciation of the content. Based on this phonological form, a statistically weighted graph of all possible realisations (pronunciation variants) within the selected language is created based on a machine-learned expert system. Finally, this graph is aligned to the speech signal using standard techniques from automatic speech recognition. The result of this process is an orthographic and a phonetic alignment (segmentation and labelling, S&L) of the recorded speech, which is then rendered into the desired target format (BPF, Emu, TextGrid) and returned to the user via the web browser.
The web application can be easily called from the web (can be found under this
URL, section BAS WebMAUS). There the user has three options to automatically segment and label his speech data. In the WebMAUS Basic a text and signal file can be uploaded, the grapheme üo phoneme conversion is automatically done and passed to MAUS, which produces the S&L. In the WebMAUS General interface, the user has the possibility to upload a signal file, together with a BAS Paritur Format (BPF) file, which already contains the canonic pronunciation. There the user additionally can choose between several options that change the outcome of the segmentation. The WebMAUS Multiple service allows the user to upload a set of file pairs (up to 300 pairs, which have to have the same base filename, e.g. signal.wav and signal.txt) which can either be a signal/text file pair or a signal/BPF file pair. This service is for batch processing of larger sets of files. The horizontal showcase enables the user to use the WebMAUS services within the WebLicht tool chain and shows the advantages of a common infrastructure. The files are uploaded to the computing center in Garching. After selecting the toolchain in WebLicht (which runs on servers in Tübingen), that contains the automatic S&L from MAUS (located on a server in München), the user can select to convert the resulting TextGrid to (Annex) format on a Server in Hamburg and not only visualize the results with the BAS viewer (again located in München), but also with the annex viewer located at the MPI in Nijmegen. The chain can be started
from here.